Čo je to Web Scraping a ako to funguje v digitálnom svete
Údaje(Data) a informácie sú dva pojmy, ktoré sa často používajú zameniteľne, ale je medzi nimi výrazný rozdiel. Údaje sa napríklad vzťahujú na časti informácií, ale nie na informácie samotné. Na druhej strane sú informácie(Information) súborom údajov, ktoré sa spracúvajú zmysluplným spôsobom. S obrovským množstvom údajov dostupných na internete sa používajú rôzne prístupy, ako je škrabanie(Web Scraping) z webu, získavanie údajov z webu(Web Harvesting) alebo extrakcia údajov(Web Data Extraction) z webu , na generovanie praktických a prevratných informácií o používaní internetu(Internet) . Ale čo presne znamenajú v online svete. Pozrime sa!
Ako funguje Web Scraping
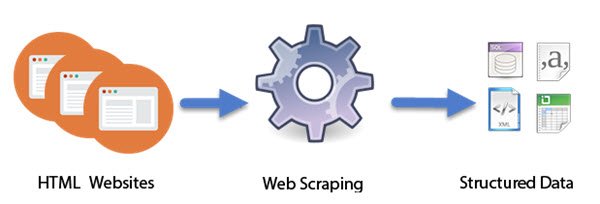
Počítačové(Computer) programy navrhnuté ako inteligentné(Intelligent) roboty vykonávajú prácu Web Scraping . Na rozdiel od zoškrabovania obrazovky, ktoré kopíruje iba pixely zobrazené na obrazovke, zoškrabovanie webu extrahuje základný kód HTML a spolu s ním aj údaje uložené v databáze. Tento prístup sa stal veľmi populárnym. V skutočnosti sa to považuje za jednu zo základných zručností, ktoré je potrebné získať v dnešnom digitálnom svete. Má niekoľko skvelých aplikácií pri zostavovaní veľkých súborov údajov, ktoré sú základom techník, ako je
- Big Data Analytics
- strojové učenie
- Umela inteligencia(Artificial Intelligence)
S rýchlym rozšírením digitálnych informácií sa prístup k veľkým údajom(Big Data) prostredníctvom Web Scraping alebo Web Data Extraction stal oveľa jednoduchším. Web Scraping však možno použiť pre digitálne podniky, ktoré sa spoliehajú na zber údajov v legitímnych(Legitimate) aj nelegitímnych prípadoch. Prvý obsahuje príklady benevolentného zoškrabovania webu(Benevolent Web Scraping Examples) , zatiaľ čo druhý obsahuje príklady škodlivého zoškrabovania webu(Malicious Web Scraping) .
Príklady benevolentného zoškrabovania webu
- Roboty vyhľadávacích(Search) nástrojov prehľadávajú stránku, analyzujú jej obsah, aby priradili hodnotenie na základe určitých zistení, napríklad Google .
- Stránky na porovnávanie cien(Price) , ktoré nasadzujú roboty na automatické načítanie cien produktov
- Spoločnosti zaoberajúce sa prieskumom trhu(Market) , ktoré používajú škrabky na extrakciu údajov zo sociálnych médií (napr. na analýzu sentimentu, osobných preferencií atď.).
Príklady škodlivého zoškrabovania webu
Web Scraping na nezákonné účely môže spôsobiť vážne finančné straty, ak sú údaje extrahované bez povolenia vlastníkov webových stránok. Dva najbežnejšie prípady použitia škodlivého Web Scraping(Malicious Web Scraping) sú cenové zoškrabovanie a krádež obsahu.
- Znižovanie cien(Price Scraping) – roboty škrabákov(Scraper) kontrolujú konkurenčné obchodné databázy, aby získali prístup k informáciám o cenách, podkopali konkurentov a zvýšili predaj.
- Krádež obsahu(Content Theft) – Táto nezákonná činnosť zahŕňa rozsiahlu krádež obsahu z cieľovej webovej stránky. Medzi typické ciele patria najmä online katalógy produktov a webové stránky, ktoré sa spoliehajú na digitálny obsah na podporu podnikania.
Dúfam, že to pomôže!

About the author
Som počítačový inžinier s viac ako 10-ročnými skúsenosťami v softvérovom priemysle, konkrétne v Microsoft Office. Napísal som články a návody na rôzne témy týkajúce sa balíka Office vrátane tipov, ako efektívnejšie využívať jeho funkcie, trikov na zvládnutie bežných kancelárskych úloh a podobne. Moje schopnosti spisovateľa zo mňa tiež robia vynikajúci zdroj pre ostatných, ktorí sa chcú dozvedieť o Office alebo len potrebujú rýchlu radu.
Related posts
Žiadne internetové pripojenie, ale zobrazuje sa ako Pripojené k webu
Čo je bitcoin, digitálna mena
Čo sa stane s vašimi online účtami, keď zomriete: Správa digitálnych aktív
Čo je temný web alebo hlboký web? Ako získať prístup a bezpečnostné opatrenia.
Výhody užívania Digital Detox a ako na to ísť
Wi-Fi vs Ethernet: Ktorý z nich by ste mali používať?
Kto vlastní internet? Webová architektúra vysvetlená
Nemôžete sa pripojiť k internetu? Vyskúšajte Complete Internet Repair Tool
Skupinová rýchla voľba pre Firefox: Dôležité internetové stránky na dosah ruky
Čo je chyba 403 Forbidden a ako ju opraviť?
Koniec životnosti programu Internet Explorer; Čo to znamená pre podniky?
Online tipy, nástroje a služby na riadenie dobrej povesti
Môže sa zrútiť celý internet? Môže nadmerné používanie zničiť internet?
10 Príklady Web 3.0: Je to budúcnosť internetu?
Počítačová kriminalita a jej klasifikácia – organizovaná a neorganizovaná
Zlyhanie programu Internet Explorer kvôli iertutil.dll v systéme Windows 10
Skontrolujte, či je vaše internetové pripojenie schopné streamovať obsah v rozlíšení 4K
Ikona siete hovorí Bez prístupu na internet, ale som pripojený
Článok o zabezpečení internetu a tipy pre používateľov systému Windows
Domain Fronting vysvetlené spolu s Dangers and